MobileNet使得在算力相对弱的移动设备端也能运行神经网络模型。本文来探讨一下MobileNet的特点。
首先,我们回顾一下标准的卷积操作,卷积的Kernel的shape为K x K x M(M为上一层输出特征图的通道数,也就是本层的输入),Kernel的个数为N,N为输出特征图的通道数。它的计算量为Dj x Dj x N x K x K x M(具体的推导方式参见上一篇博客)。标准CNN在移动设备端无法运行的一个原因是卷积的计算量很大。
MobileNet引入了被称为depthwise separable convolution的卷积操作来近似标准的卷积操作。
注:在图像处理相关的领域,卷积操作处理的数据通常是3维(不是我们理解的3D),这3维数据分别表示其长宽和通道数。其中,通道数有时也叫深度depth。在MobileNet的论文中,它引入的卷积操作叫这个名字估计就是这样来的。
depthwise separable convolution
注:输入特征图的长宽均为Di,通道数为M。
depthwise separable convolution分成两步:
depthwise convolution
第一步:采用shape为(K, K, 1)的Kernel对输入特征图做卷积。根据标准CNN卷积的规则,Kernel的通道数需要与输入特征图的通道数一致才能进行卷积操作。因此,这里的shape为(K, K, 1)的Kernel只对特征图的一个通道做卷积。因为,输入特征图有M个通道,因此需要M个shape为(K,K,1)的Kernel。
在形象化地解释一下,我们把输入层看成是M层玻璃重叠在一起,对每层玻璃我们都用一个不同的镜片(Kernel)去检查,检查完了以后输出的特征图还是M层。标准的卷积相当于拿着一个厚度为M的Kernel去同时检查所有M层的玻璃,检查完后输出的特征图只有1层了。
它的参数量为M个Kernel的参数量,即K x K x 1 x M。论文中假设输入和输出特征图的长宽都是一致的(也是Di,这可以通过选择合适的padding, stride和kernel大小达成),因此输出图总共有Di x Di x M个元素,每个元素需要K x K x 1次计算。因此,它的计算量为Di x Di x M x K x K。
这一步是对每个输入通道分开处理的,从这里我们可以看出它为什么叫depthwise separable convolution。
pointwise convolution
第二步:经过上一步处理后,特征图还是(Di, Di, M), 这一步是利用N个(1 x 1 x M)个Kernel进行标准的卷积操作。输出的特征图为(Di, Di, N)。
由于第一步中没有将输入通道进行融合,这一步是通过1x1的卷积将输入通道融合在一起,也叫pointwise convolution。之所以叫这个名字,可能是因为每个卷积只处理1个cell吧。
这一步的参数量为1 x 1 x M x N(每个kernel的shape为(1x1xM),总共有N个Kernel)。计算量为Di x Di x N x 1 x 1 x M(输出特征图总共有Di x Di x N 个元素,每个元素需要的计算量为1x1xM)
这里对比一下MobileNet用到的depthwise separable convolution和标准卷积的参数量和计算量。
| item | depthwise separable convolution | stand convolution | 比例 |
|---|---|---|---|
| 参数量 | K x K x 1 x M + 1 x 1 x M x N | K x K x M x N | 1/N + 1/(KxK) |
| 计算量 | Di x Di x M x K x K + Di x Di x N x 1 x 1 x M | Di x Di x N x K x K x M | 1/N + 1/(KxK) |
由此可见,mobilenet的参数量和计算量都大幅度减少,如果采用3x3的Kernel的话,那么MobileNet的速度是标准CNN的9倍。因此,MobileNet可以在移动端能进行AI推理。以上就是MobileNetV1的核心。
depthwise separable convolution block
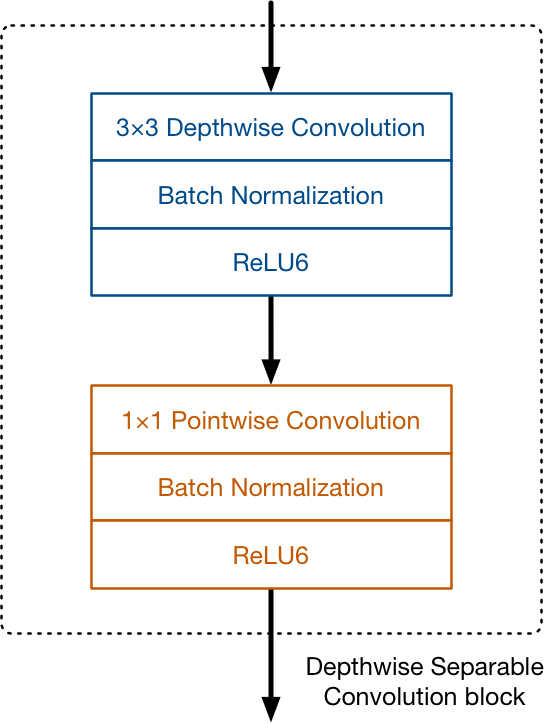
depthwise separable convolution block 是组成MobileNet的基本单元,结构如下图所示。在depthwise convolution和pointwise convolution之后分别加了batch normalization和Relu6的激活层。
MobileNet的结构
MobileNet的整体网络结构包括以下两部分:
- 一层标准的CNN卷积层+13层depthwise separable convolution block
- global average pooling和最后分类的softmax层
其中,第一部分为从输入图像中提取特征,第二部分是用于分类。我们在keras中将mobilenet的网络结构打印出来,如下:
from keras.applications import MobileNet |
我把中间部分省略掉了,只保留了开始和最后部分。可以看到,输入图像是224x224的RGB图像,经过第一部分的若干卷积层后变成了7x7x1024的特征图,然后进行分类。总共的参数量在420w左右。
分类的一般的做法是,将7x7x1024的特征图进行Flatten变成了1x50176的向量,再通过Dense层进行分类。但是这样的话,最后全连接层的参数量将会有50,176,000个参数,这可能导致网络非常容易过拟合。
MobileNet采取的做法是先进行global average pooling,将其变成了1x1024的向量,再接上drop,最后再分类。这样参数量就下降很多,起到了防止过拟合的效果。
顺便说下Global Average Pooling,它是将输入的特征图的每个通道上的所有元素取平均值,因此7x7x1024的特征图就变成了1x1x1024的特征图。
总结
MobileNet的核心是depthwise separable convolution block,它采用depthwise的卷积对每个通道分别做卷积,然后采用1x1的pointwise卷积将多个通道特征融合产生新的特征。在最后的分类阶段,采用global average pooling和dropout来防止过拟合。它的计算量是普通卷积网络的1/9,因此MobileNet能够在在移动端运行。