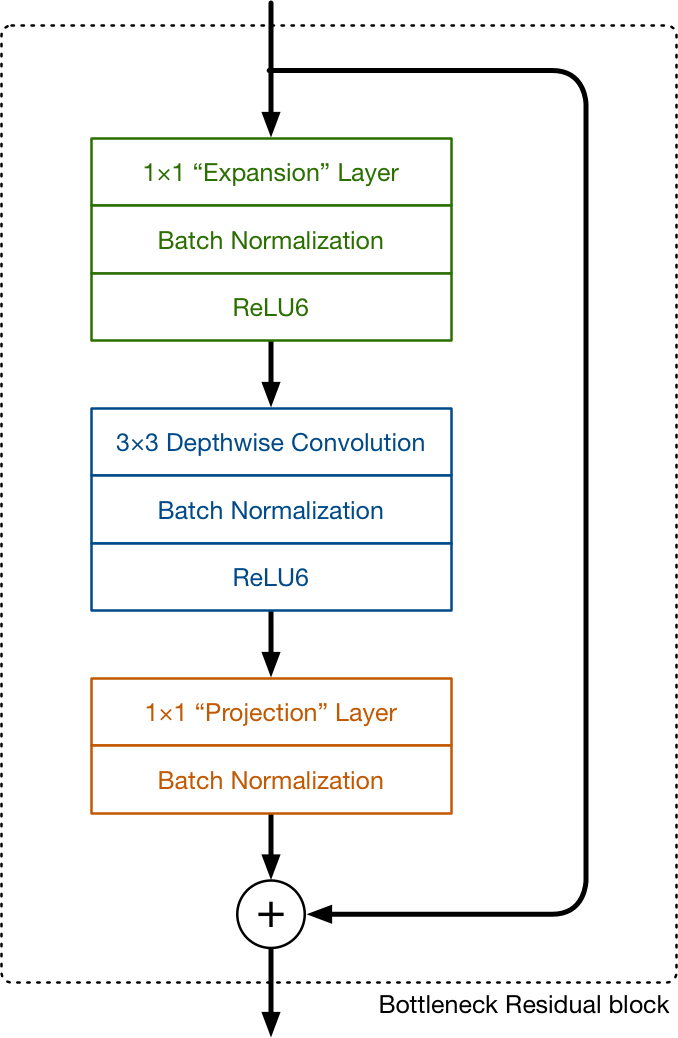
bottleneck residual block
MobileNet v1采用depthwise separable convolution作为其主要的building block来代替标准的卷积操作,以达到减少计算量的目的。而MobileNet v2可以认为是全新的设计,里面有两个核心概念linear Bottleneck和inverted resiudal。构成MobileNet v2的基本结构叫做bottleneck residual block. 如下图所示:
图片来自:https://machinethink.net/
bottleneck residual block 包含了三个部分:
- 1x1 expansion layer,就是标准的1x1的卷积,它将输入的feature map的通道进行expand。有关超参expand ratio,来控制expand比例(论文作者的实验结果是expand ratio=6的时候效果最好)。比如输入的feature map有24个通道,扩张6倍后变成144个通道。
- 与MobileNetv1类似的depthwise convolution
- 与MobileNetv1类似的pointwise convolution,在MobileNetv2中被称为了Projection layer,且最后没有relu6的激活函数。
因为这个Block最后的projection layer没有激活函数,且它的左右是将输出的通道数减少,看起来有点像瓶颈,这就是linear bottleneck。
对于bottleneck residual block的理解,machinethink的博主给出了一个非常巧妙的类比,expansion layer就像是对输入的feature map做解压缩,然后depthwise convolution对解压缩出的数据做过滤和处理,最后projection layer再一次对数据做压缩。
对于invertest residual的理解,直观来看它就是将输入和输出直接做element wise的相加,有助于网络误差的传递。至于为什么叫inverted residual,我们得首先看看什么是residual。
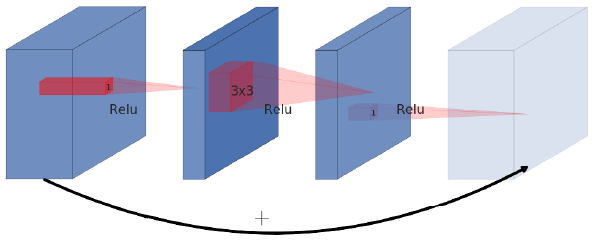
原始的residual connection的结构如下图所示:
图片来自towardsdatascience.com
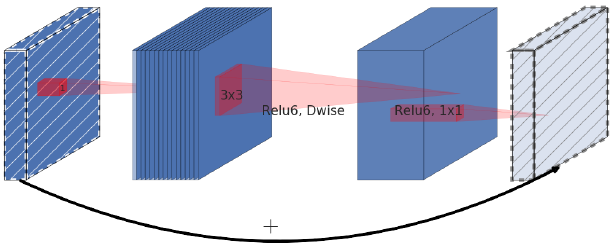
可以看到它的输入和输出层的通道数是比中间层的通道数多的,而Mobilenetv2的bottleneck residual block中,输入和输出层的通道数比中间层要少,因此论文作者称之为inverted residual。
以下为inverted residual的图示:
图片来自towardsdatascience.com
Mobilenet v2结构
了解了MobileNetv2的核心building block后,MobileNetv2的整体网络结构就呼之欲出了。与MobileNetv1类似,也是分成2大部分:
- 1个标准的卷积操作+若干个bottleneck residual block
- global average pool和用于分类的dense层
同样,我们在keras中将mobilenetv2的网络结构打印出来,如下:
from keras.applications import MobileNetV2 |
由此可见,mobilenettv2的网络参数为350w左右,比MobileNetv1少了70w个参数。
总结
Mobilenet v2引入了linear bottleneck和inverted residual两个核心概念,参数量比v1少了近70w,预测的精度却与v1相当。